Kiến Trúc Hệ Thống Business Intelligenct (BI) Đa Nguồn Dữ Liệu
Trong quá trình tư vấn và triển khai hệ thống Business Intelligence (BI) cho nhiều doanh nghiệp ở các lĩnh vực khác nhau — từ bán lẻ, sản xuất cho đến FMCG – đội ngũ chuyên gia tại IdeaLab nhận ra rằng thách thức lớn nhất không nằm ở công cụ, mà nằm ở dữ liệu. Và cụ thể hơn, đó là bài toán tổng hợp dữ liệu từ nhiều hệ thống khác nhau, vốn đang rải rác ở khắp nơi, ví dụ SAP quản lý tài chính, sản xuất, DMS theo dõi phân phối, CRM lưu trữ thông tin khách hàng, còn các file Excel vẫn là “đặc sản” ở nhiều phòng ban. Một hệ thống BI mạnh mẽ không thể chỉ nhìn vào một nguồn dữ liệu. Nó cần hợp nhất tất cả. Nhưng làm thế nào để biến những mảnh rời rạc ấy thành một dòng chảy thông suốt, sạch sẽ và có thể phân tích được?
Khi dữ liệu là những mảnh ghép lệch chuẩn
Trong thời đại số hóa, dữ liệu doanh nghiệp không còn tập trung ở một nơi.
Thay vào đó, dữ liệu được phân tán ở nhiều hệ thống:
SAP: quản trị tài chính, chuỗi cung ứng, sản xuất
DMS: quản lý kênh phân phối
CRM: theo dõi khách hàng và bán hàng
Excel: vẫn phổ biến trong vận hành nội bộ
API bên ngoài: cung cấp dữ liệu thị trường, đối tác,...
Để ra quyết định chính xác, doanh nghiệp cần tổng hợp, xử lý và phân tích tập trung các nguồn dữ liệu này trong một nền tảng BI.
Các thách thức khi xử lý đa nguồn dữ liệu
- Không đồng nhất định dạng: mỗi hệ thống lưu trữ dữ liệu khác nhau (
SQL,Excel,CSV,JSON…) - Tần suất cập nhật không đồng đều:
SAPcập nhật realtime,Excelcập nhật thủ công - Từ khóa và định danh khác nhau: “Khách hàng” trong
CRMcó thể khác cách ghi trongDMS - Khó truy vết & kiểm soát chất lượng dữ liệu
Khi đưa các dữ liệu này vào BI mà không xử lý triệt để, thì báo cáo không chỉ sai lệch mà còn gây hiểu nhầm nghiêm trọng cho người ra quyết định.
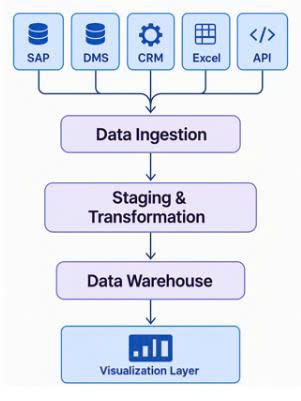
Kiến trúc BI đa nguồn dữ liệu: từ rời rạc đến hợp nhất
Giải pháp nằm ở việc thiết kế một kiến trúc BI chuẩn hóa, giúp dữ liệu từ nhiều nguồn có thể “nói chuyện” được với nhau.
Dưới đây là kiến trúc chúng tôi thường áp dụng trong các dự án BI đa nguồn:
Sơ đồ kiến trúc tổng thể
Từng tầng trong kiến trúc và vai trò của nó
1. Tầng ingestion: Thu thập dữ liệu từ mọi nguồn
Đây là nơi dữ liệu “thô” được lấy về từ các hệ thống nguồn. Với SAP, chúng tôi thường kết nối qua OData hoặc sử dụng BAPI nếu hệ thống cũ hơn. DMS thường có thể trích xuất trực tiếp từ database hoặc qua file batch FTP. CRM như Haravan hay Salesforce thì dùng API. Excel thì phổ biến nhất: hoặc người dùng upload định kỳ vào SharePoint, hoặc bot tự động lấy từ một folder đồng bộ.
Ở tầng này, tốc độ chưa quan trọng bằng độ tin cậy và tính lặp lại. Việc xây dựng lịch trình định kỳ (scheduler) và log chi tiết cho mỗi lần thu thập là yếu tố quyết định độ ổn định của toàn bộ hệ thống về sau.
2. Tầng xử lý: Làm sạch, chuẩn hóa và mapping
Sau khi thu thập, dữ liệu được đưa vào một khu vực gọi là staging layer – nơi diễn ra các thao tác làm sạch, mapping khóa, xử lý định danh trùng, chuẩn hóa đơn vị, định dạng thời gian, v.v.
Một ví dụ điển hình: trong SAP, mã khách hàng có thể là KH0001, trong CRM lại là CUST_01, còn trong Excel thì đơn giản là “Nguyễn Văn A”. Việc thiết lập master data và logic mapping sẽ giúp BI hiển thị đúng theo góc nhìn quản trị.
Các công cụ như dbt (data build tool), Apache Spark hoặc thậm chí các pipeline xử lý bằng Python đều được sử dụng ở đây tùy theo quy mô và độ phức tạp.
3. Tầng lưu trữ: Data Warehouse – nơi dữ liệu trở nên có cấu trúc
Dữ liệu sau khi xử lý sẽ được đẩy vào Data Warehouse (DWH) – đây là trung tâm dữ liệu phân tích. Tùy quy mô và ngân sách, chúng tôi có thể chọn các giải pháp on-premise như SQL Server, hoặc các giải pháp cloud hiện đại như Amazon Redshift, BigQuery, Snowflake. Với dự án startup hoặc ngân sách hạn chế, ClickHouse cũng là một lựa chọn rất tốt cho các truy vấn phức tạp.
Một điểm quan trọng ở tầng này là mô hình dữ liệu. Nếu thiết kế theo kiểu bảng dẹt (flat table), báo cáo sẽ dễ làm nhưng khó mở rộng. Nếu thiết kế kiểu star schema hoặc data vault, thì phức tạp hơn lúc đầu nhưng sẽ tiết kiệm được rất nhiều công sức khi hệ thống lớn lên.
4. Tầng trình bày: Dashboard, báo cáo và alert
Đây là nơi người dùng cuối tiếp xúc với dữ liệu – thường là qua các công cụ như Power BI, Tableau, hoặc Superset (open-source). Với người quản lý, họ cần một cái nhìn tổng quan (high-level). Với bộ phận vận hành, họ cần báo cáo chi tiết từng SKU, từng khu vực. Và với bộ phận tài chính, họ cần số liệu khớp tuyệt đối với hệ thống kế toán.
Một hệ thống BI tốt cần phân quyền chặt chẽ, hỗ trợ gửi báo cáo định kỳ (qua email, Slack, Zalo…) và khả năng tự tạo dashboard (self-service BI) cho người dùng không kỹ thuật.
Kết luận: BI không đơn thuần là báo cáo đẹp
Đằng sau một dashboard trực quan, hiện đại là một kiến trúc dữ liệu được thiết kế bài bản, hiểu rõ từng hệ thống nguồn, xử lý đúng logic nghiệp vụ và đặc biệt là khả năng mở rộng khi doanh nghiệp phát triển.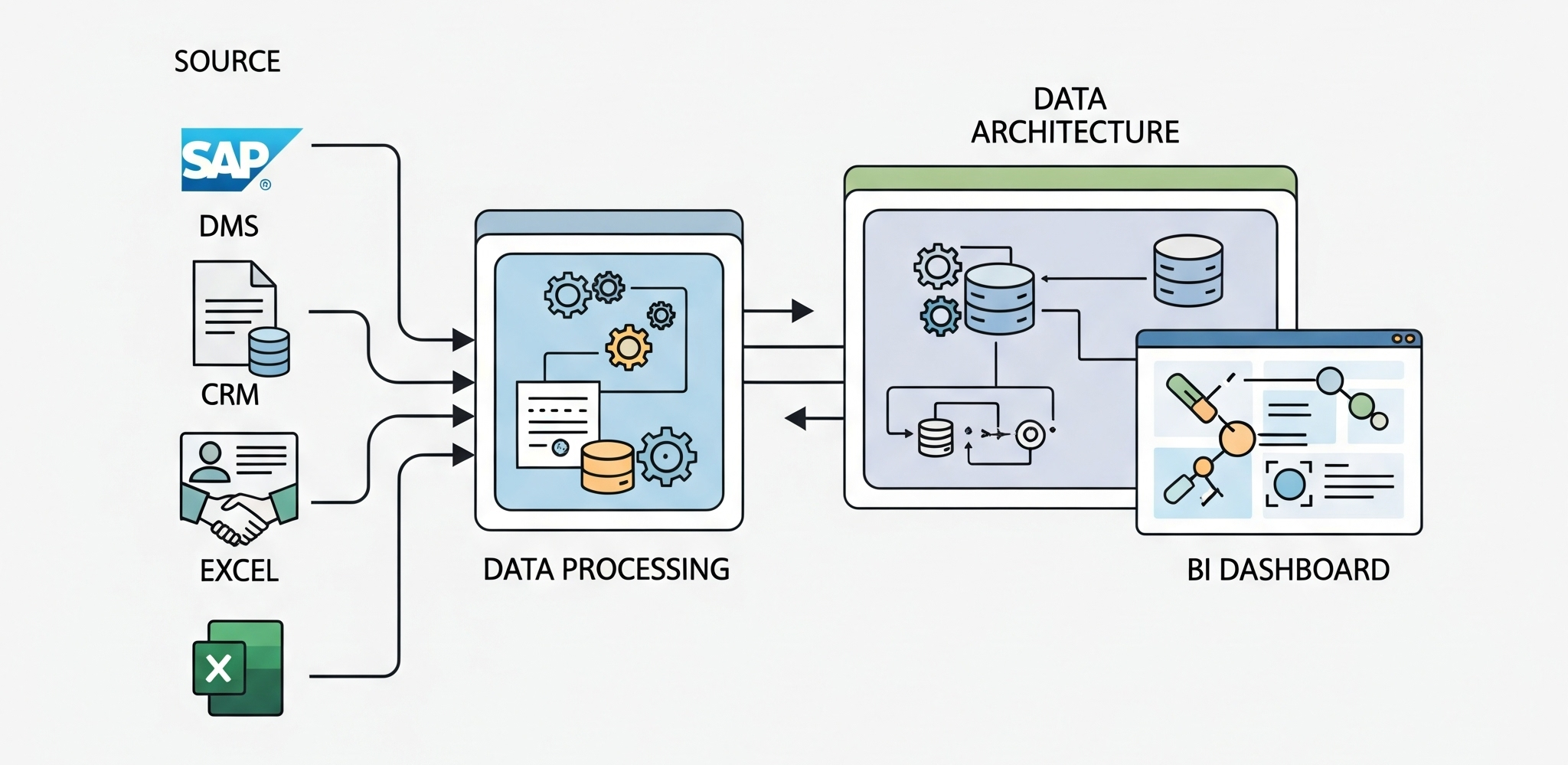
Nếu bạn đang có dữ liệu nằm rải rác ở SAP, DMS, CRM, Excel và chưa biết bắt đầu từ đâu, lời khuyên của tôi là: hãy bắt đầu từ việc làm chủ dữ liệu – hiểu dữ liệu của mình, xác định rõ mục tiêu phân tích, rồi từ đó thiết kế hệ thống BI phù hợp. Công cụ chỉ là phần phụ. Kiến trúc mới là phần cốt lõi.